



")
Prof. Sławomir T. Wierzchoń laureatem konkursu Polskiego Towarzystwa Informatycznego


Prof. Sławomir T. Wierzchoń z Zespołu Podstaw Sztucznej Inteligencji został laureatem prestiżowego konkursu Polskiego Towarzystwa Informatycznego. Książka pt. "Metaheurystyki. Algorytmy optymalizacji numerycznej" napisana wspólnie z dr Grzegorzem Sroką z Wydziału Matematyki i Fizyki Stosowanej Politechniki Rzeszowskiej zdobyła nagrodę I stopnia w Konkursie na Najlepszą Polską Książkę Informatyczną 2026 r. organizowanym przez Polskie Towarzystwo Informatyczne.
W tegorocznym konkursie konkurencja musiała być bardzo duża, ponieważ kapituła przyznała nagrody jeszcze czterem innym książkom przyznając po dwie nagrody ex aequo II i III stopnia. Gala wręczenia nagród konkursu Polskiego Towarzystwa Informatycznego na Najlepszą Książkę Informatyczną była punktem kulminacyjnym obchodów Światowego Dnia Telekomunikacji i Społeczeństwa Informacyjnego oraz 45-lecia PTI.
Więcej…Prof. Sławomir T. Wierzchoń laureatem konkursu Polskiego Towarzystwa Informatycznego
Odporność na transformacje funkcji celu jako miara jakości metaheurystyki
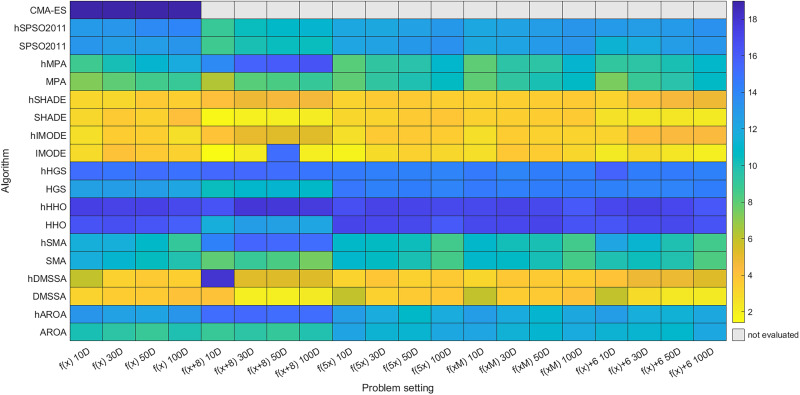

W czasopiśmie Applied Soft Computing, wiodącym wydawnictwie w dziedzinie badań i zastosowań soft computing, będącym oficjalnym czasopismem Światowej Federacji Soft Computing (WFSC), ukazał się artykuł doktora Grzegorza Sroki z Katedry Analizy Nieliniowej Politechniki Rzeszowskiej i profesora Sławomira Wierzchonia z Zespołu Podstaw Sztucznej Inteligencji IPI PAN pt. „Robustness and invariance of hybrid metaheuristics under objective function transformations” (doi: 10.1016/j.asoc.2026.114799). Pierwotną wersję artykułu umieszczono w repozytorium arXiv we wrześniu 2025 r.
Więcej…Odporność na transformacje funkcji celu jako miara jakości metaheurystyki - praca prof....
Raport - Analiza możliwości wykorzystania sztucznej inteligencji w obszarze badania dostępności cyfrowej

Pracownicy firmy Sages oraz Instytutu Podstaw Informatyki PAN na zlecenie Ministerstwa Cyfryzacji wspólnie przygotowali raport poświęcony możliwościom wykorzystania sztucznej inteligencji w obszarze badania dostępności cyfrowej. Raport obecnie został udostępniony przez Ministerstwo na stronie w domenie GOV.pl pod adresem: gov.pl/(...)/dostepnosc-cyfrowa/raport--analiza-mozliwosci-wykorzystania-sztucznej-inteligencji-w-obszarze-badania-dostepnosci-cyfrowej.
W raporcie zebrane zostały rekomendacje, dane, przykłady zastosowań oraz wnioski dotyczące tego, gdzie AI może realnie wspierać analizę i zapewnianie dostępności cyfrowej, a gdzie nadal kluczową rolę odgrywa wiedza ekspercka.
Postkwantowa ochrona informacji w sieciach 6G: wyzwania i kierunki rozwoju

W czasopiśmie ACM Computing Surveys (najwyższy współczynnik wpływu - 28.0 2025 IF w grupie czasopism JCR "Computer Science, Theory & Methods") ukazał się artykuł Profesora Józefa Pieprzyka z Zespołu Kryptografii IPI PAN pt. "From 5G to 6G: A Survey on Security, Privacy, and Standardization Pathways".
Przedstawione wyniki wskazują, że przejście od 5G do 6G radykalnie zwiększa powierzchnię ataku poprzez integrację AI, IoT oraz przetwarzania brzegowego, co wymusza fundamentalne zmiany w kryptografii i ochronie informacji . W szczególności rosnące zagrożenie ze strony komputerów kwantowych prowadzi do konieczności wdrażania kryptografii postkwantowej (np. schematów opartych na kratkach) oraz integracji rozwiązań takich jak QKD w architekturze sieci. Przewiduje się, że wyniki te znajdą zastosowanie w projektowaniu „crypto-agile” protokołów 6G, hybrydowych systemów klasycznych–kwantowych oraz w nowych modelach zarządzania ryzykiem, gdzie bezpieczeństwo stanie się cechą wbudowaną (security-by-design), a nie jedynie warstwą ochronną.
Więcej…Postkwantowa ochrona informacji w sieciach 6G: wyzwania i kierunki rozwoju
Rusza rekrutacja uzupełniająca do Szkoły Doktorskiej Technologii Informacyjnych i Biomedycznych PAN na rok akademicki 2025/2026
![]()
2 marca rusza rekrutacja uzupełniająca do Szkoły Doktorskiej Technologii Informacyjnych i Biomedycznych Instytutów PAN (TIBPAN) na rok akademicki 2025-2026. TIBPAN prowadzi kształcenie interdyscyplinarne przygotowujące do uzyskania stopnia doktora w następujących dyscyplinach:
- informatyka techniczna i telekomunikacja,
- inżynieria biomedyczna,
- nauki medyczne.
Termin nadsyłania zgłoszeń na adres Instytutu Podstawowych Problemów Techniki PAN mija 8 marca 2026 r.
Więcej…Szkoła Doktorska TIB PAN - rekrutacja uzupełniająca 2025/2026