


")
Learning from positive and unlabeled data - article at the AISTATS 2025 conference

A paper co-authored by Paweł Teisseyre has been published in the proceedings of the AISTATS 2025 (Artificial Intelligence and Statistics) conference. Paper PU learning @ AISTATS 2025.
This is a joint work with research group from KU Leuven University (Prof. Jesse Davis, Dr. Jessa Bekker, and Timo Martens). The article focuses on learning from positive and unlabeled data (Positive-Unlabeled learning / PU learning).
What is PU learning?
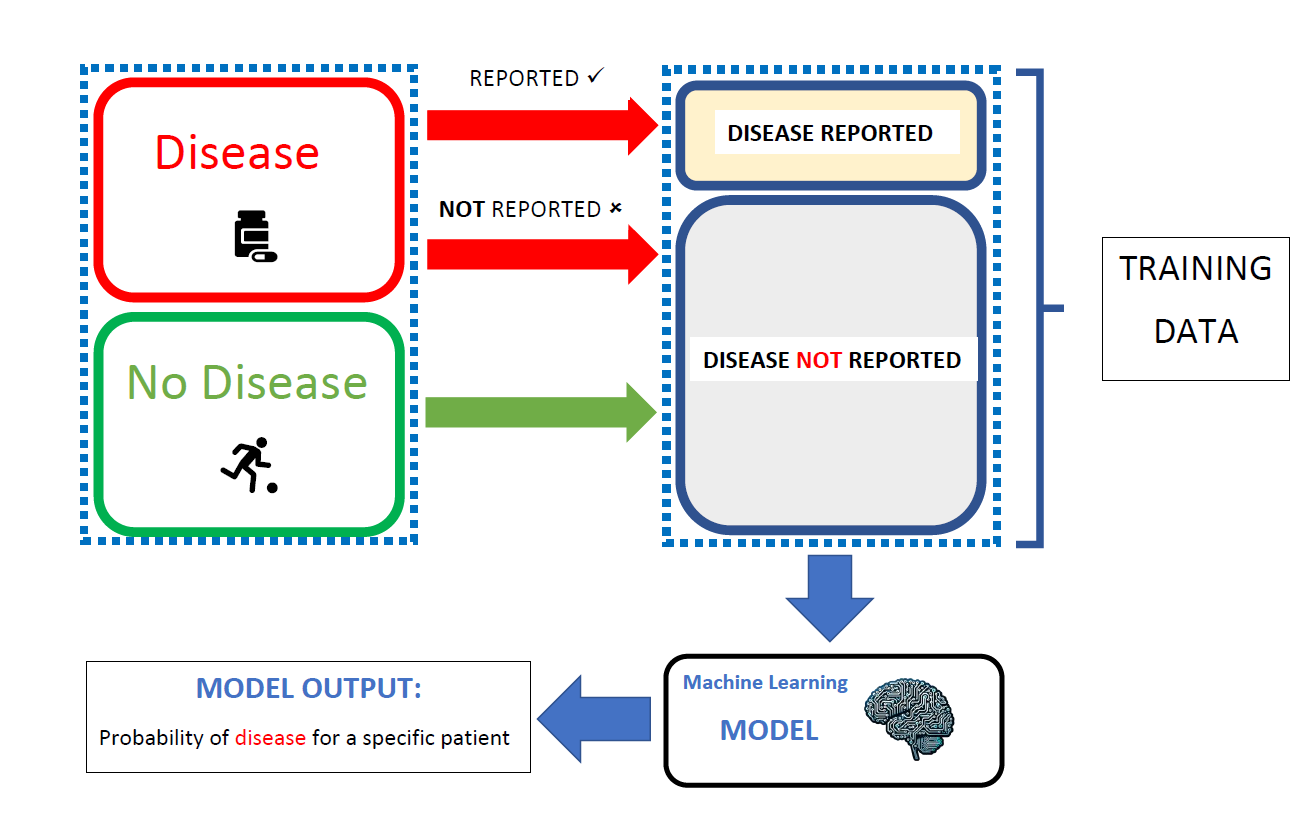
Standard learning models, used for example in medicine to predict the occurrence of disease episodes in patients, require the collection of both positive (confirmed disease occurrence) and negative (confirmed absence of disease) observations.
In practice, training data can be gathered based on patient reports: for instance, patients suffering from episodic headaches report migraine attacks through dedicated applications. The data collected in this way is typically prone to errors, as some episodes (positive cases) are not reported. Two groups of patients can be distinguished:
- Individuals reporting disease episodes (positive observations),
- Individuals not reporting disease episodes, among whom there are both positive cases (patients who did not report the disease) and healthy individuals. Therefore, this group is treated as unlabeled observations.
It turns out that learning from such incomplete reporting data is still possible. However, it requires the use of advanced mathematical techniques that account for the fact that the labeling mechanism may depend on individual patient characteristics.
PU learning methods are being developed by the Statistical Analysis and Modeling group at ICS PAS (Prof. Jan Mielniczuk, Ph.D., D.Sc., Paweł Teisseyre, Ph.D., D.Sc., Małgorzata Łazęcka, Ph.D.). The algorithms developed have been described in previous works:
- Wojciech Rejchel, Paweł Teisseyre, Jan Mielniczuk: Joint empirical risk minimization for instance-dependent positive-unlabeled data, Knowledge-Based Systems, 2024: https://www.sciencedirect.com/science/article/abs/pii/S0950705124010785,
- Paweł Teisseyre, Konrad Furmanczyk, Jan Mielniczuk: Verifying the Selected Completely at Random Assumption in Positive-Unlabeled Learning, Proceedings of the European Conference on Artificial Intelligence ECAI’24, 2024: https://ebooks.iospress.nl/volumearticle/69770,
- Małgorzata Łazęcka, Jan Mielniczuk, Paweł Teisseyre, Estimating the class prior for positive and unlabelled data via logistic regression, Advances in Data Analysis and Classification, 2021 https://link.springer.com/article/10.1007/s11634-021-00444-9.